Naive text summarisation
A few years ago, around the time I was writing my Bachelor’s thesis, I became interested in text summarisation. So I decided to dedicate a small portion of my thesis (about a week) to exploring it. At the time, I was very aware of methods using machine learning that produced very sophisticated summaries of long bodies of text. But I didn’t have any knowledge in that area, so I considered it a challenge to see how far I could get with algorithmic thinking and statistics.
What I ended up with wasn’t great, and combined with my lack of expertise, I decided to refer to it as naive! But for me, it wasn’t so much about the results but the journey in getting there.
You can give it a try here - but be warned it’s really not that great! It works best on text that is structured to that of a newspaper article - many paragraphs where each represents a single point.
How it works
The following is an abridged excerpt from my thesis explaining the thinking behind it:
This algorithm offers a simpler form of text summarisation; it takes an input
text and outputs a reduced form of it, averaging around one sentence per
paragraph. The algorithm used for this summarisation is based on TextRank, and
creates sentence rankings in the form of a weighted graph. The algorithm starts
by receiving a piece of text and splitting it into paragraphs (with delimiter
\n\n).
Each paragraph is then further split into sentences, which will be given a score. This score is generated by an intersection function, which takes as input two sentences and returns a score based on the words they share. This is done by splitting both sentences into words, counting the words both sentences share and then normalising this result by dividing by the average sentence length.
This can be formally expressed as:
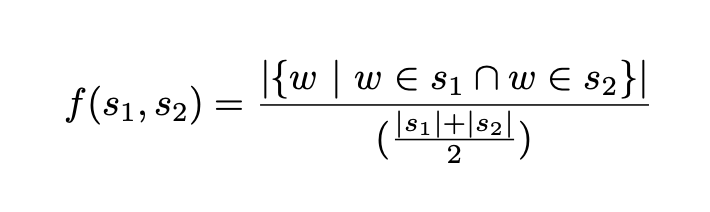
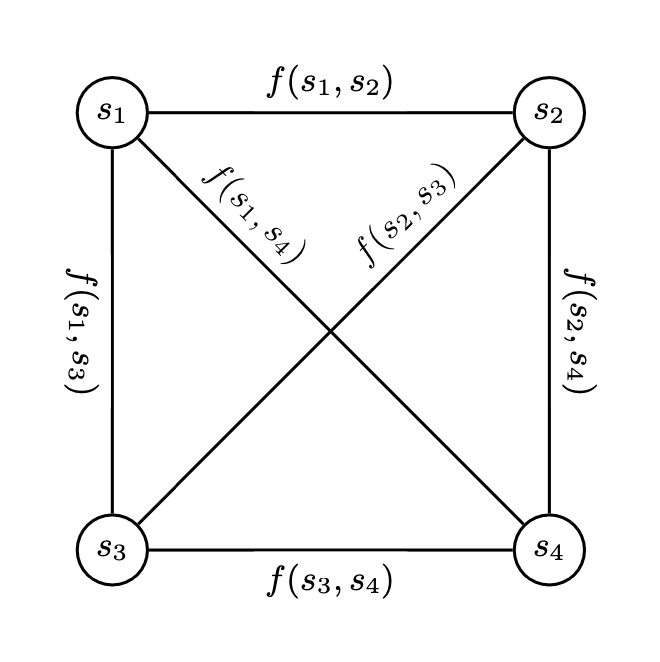
A connected weighted graph is then implemented by using a two-dimensional array, where the intersection values for each combination of sentences are stored. Each sentence is considered a node, and the intersection score of two sentences is considered the edge between those two nodes.
The score for a single sentence is the sum of its intersection values with all other sentences (sum of all edges of that node), formally expressed as:
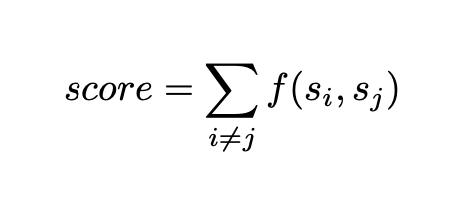
A high sum of intersection values indicates that the sentence is similar to all other sentences, implying that it contains similar information to the other sentences. This characteristic makes it a good candidate for summarising a paragraph.
Finally, to build the summary, the algorithm selects the top scoring sentence of each paragraph and compiles this into a summary to form the reduced version of the text.
This algorithm works well under two assumptions. The first is that the text has been split into paragraphs in a meaningful manner, where the sentences in a paragraph all relate to a singular point being made. If the content of the text is split randomly into different paragraphs, it could be possible that the summarised version contains redundant information. The second assumption is that a high intersection score between two sentences means that they contain the same information. This may not always be the case, and this becomes evident when you try and summarise less structured pieces of text.
Overall, it was a fun thing to explore despite not being that competent - which presents an opportunity to make a version 2 improving it!